

Speech-to-text или речь в текст – такой формат востребован повсеместно благодаря очевидному удобству и экономии времени и… Про туннельный синдром, мышечные миалгии и прочее – речь пойдет в другом посте, но суть понятна )
Итак, вашему вниманию, подборка бесплатных AI нейросетей для перевода речи в текст с разным функционалом, в том числе с поддержкой API.
Их возможности тоже постараюсь описать и снабдить скриншотами.
•
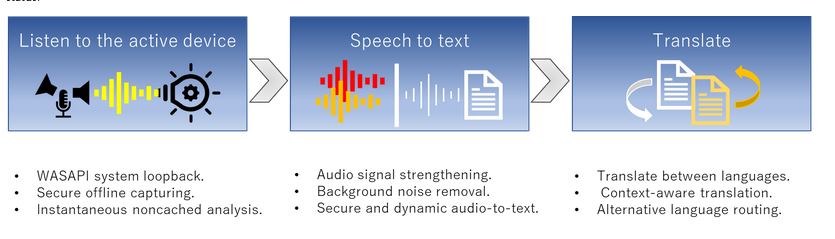
Hanami Live Translator - это инструмент, который захватывает любой звук, поступающий через динамик и микрофон Windows. Его можно использовать для автоматического перевода устных слов с одного языка на другой.
Приложение использует легкую многопроцессорную обработку, обрабатывает аудио по фрагментам и использует SpeechRecognition для преобразования двоичного аудио в текст.
Оно также использует Selenium для имитации веб-вызовов для серверов Deepl без вызовов API, а в комплекте с приложением поставляется портативная версия Google Chrome с соответствующим драйвером Chrome.
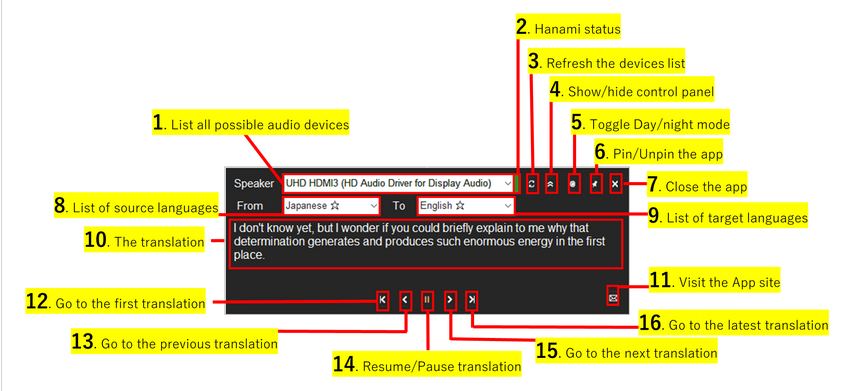
В приложении также есть переключатель дневного/ночного режима, кнопка pin для удержания приложения на вершине и пункт меню refresh для обновления списка устройств.

Поддержка русского языка – есть.
Открыто для скачивания и работы для Windows.
•
Это расширение Chrome позволяет вести голосовые разговоры с ChatGPT. Оно добавляет кнопку под полем ввода, которая позволяет записать свой голос и отправить вопрос в ChatGPT.
Также у разработчика есть и другие продукты: вот весь доступный список.
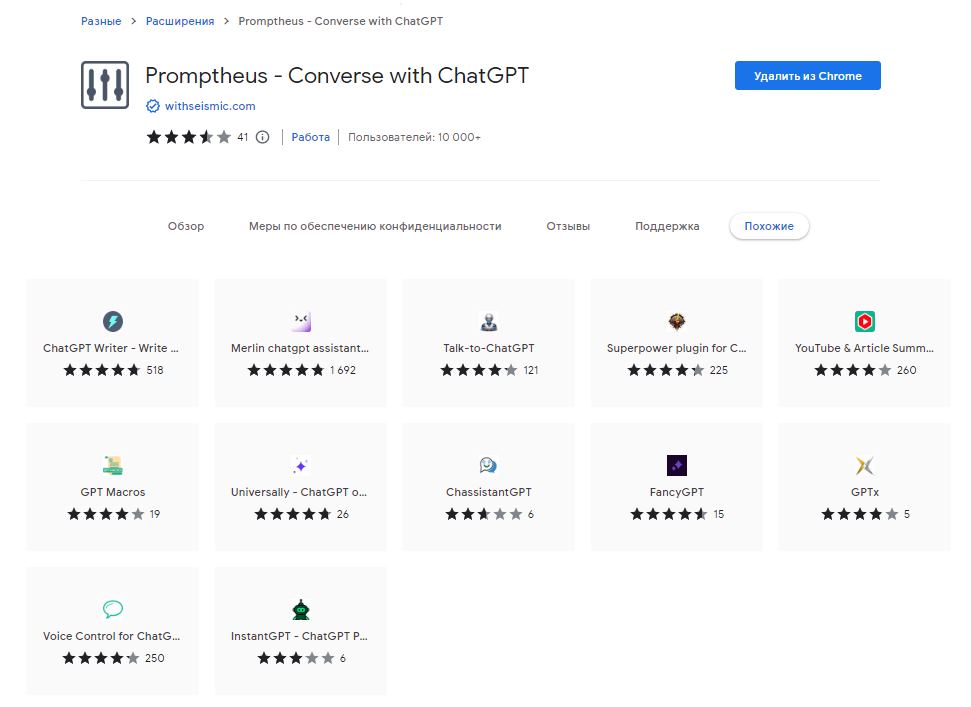
Это позволяет легко взаимодействовать с интеллектуальным собеседником и изучать возможности передового искусственного интеллекта. Если вы интересуетесь искусственным интеллектом или ищете новый способ взаимодействия с технологиями, это расширение - отличный выбор.
Особенности:
• Запись голосового ввода и отправка его в ChatGPT;
• Чтение ответов вслух (или отключение, если вы предпочитаете читать);
• Поддержка нескольких языков;
• Запишите голос, нажав на кнопку микрофона, или... пробел;
• Нажмите и удерживайте ПРОБЕЛ (вне ввода текста) для записи. Отпустите, чтобы отправить.
Используется встроенная функция распознавания речи из браузера.
Поддержка русского языка – есть.
Поддержка браузеров:
• Chrome для настольных компьютеров;
• Edge (только для Windows).
•
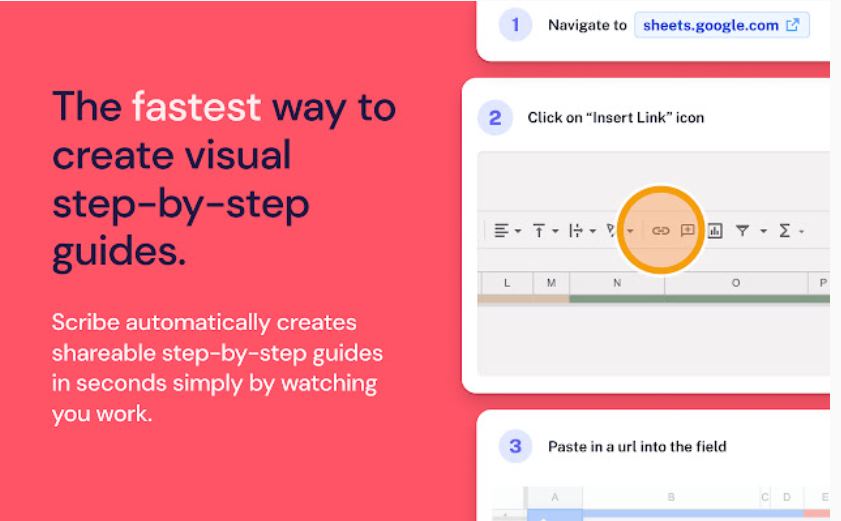
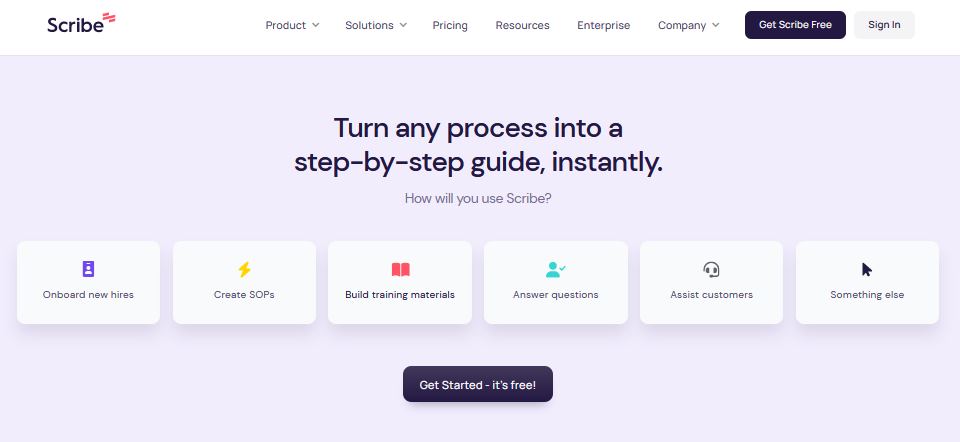
Scribe - это нейросеть для перевода речи в текст с удобным пошаговым визуальным руководством. При использовании диктофона Scribe - во время выполнения процесса - инструмент автоматически генерирует руководство с скриншотами, инструкциями и кликами.
Интерфейс нейросети позволяет пользователям вносить правки и настройки, такие как дополнительные детали, примечания и брендинг. После завершения работы руководство можно легко распространить через URL-ссылки, экспортировать в PDF-документ, встроить в существующие инструменты и вики или экспортировать в Confluence.
Инструмент поддерживает интеграцию с Chrome и Edge, а также с настольными платформами.
Scribe предлагает бесплатную версию и дополнительные платные функции для компаний.
•
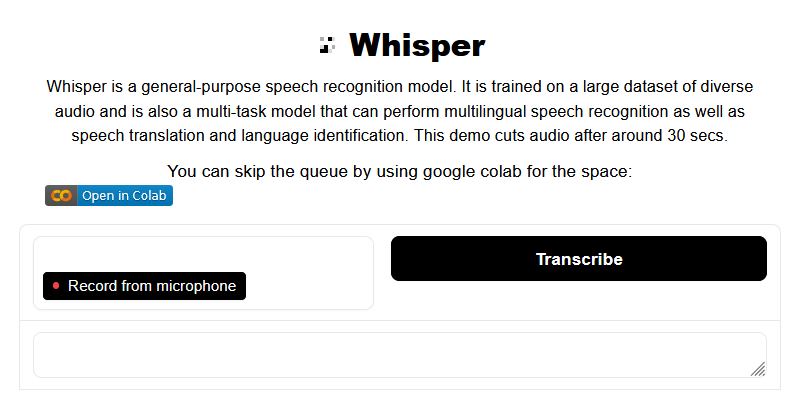
Whisper - это нейросеть распознавания речи.
Она обучена на большом наборе данных разнообразных аудиозаписей и является многозадачной моделью, которая может выполнять многоязычное распознавание речи, а также перевод речи и идентификацию языка.
Варианты тарификации, включая безоплатную модель.
Поддержка русского языка – есть.
•
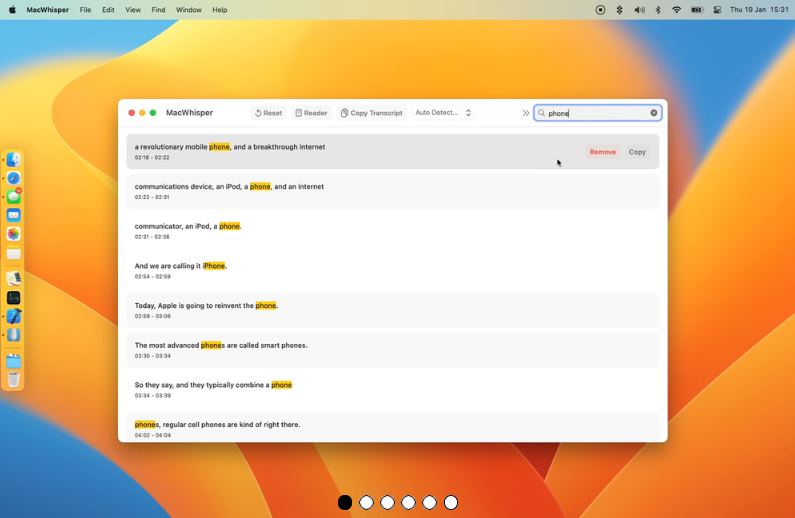
По названию очевидно, что нейросеть для перевода речи в текст заточена под MacOS.
Простая запись и расшифровка аудиофайлов: просто перетащите аудиофайлы, чтобы получить транскрипцию.
Вся транскрипция выполняется на вашем устройстве, никакие данные не покидают ваш компьютер. Это делает MacWhisper хорошим приложением для чувствительных аудиофайлов.
• Экспорт субтитров .srt и .vtt, экспорт csv;
• Получайте точные текстовые транскрипции за считанные секунды (до ~30x в реальном времени);
• Поиск по всей транскрипции и выделение слов;
• Воспроизведение аудио и синхронизация с транскриптами;
• Поддерживает 100 различных языков, включая русский;
• Копирование всей расшифровки или отдельных фрагментов;
• Режим чтения;
• Звезда/избранные сегменты;
• Компактный режим (скрытие временных меток);
• Автоматическое удаление "хм", "уф" и других подобных слов-заполнителей;
• Перетаскивание непосредственно из голосовых заметок;
• Редактирование и удаление сегментов из транскрипта;
• Выберите язык транскрипции (или используйте автоматическое определение);
• Поддерживаемые форматы: mp3, wav, m4a и видео mp4;
• Поддерживает модели Tiny и Base.
Поддержка русского языка – есть.
•
Программный пакет VoxSigma Speech-to-Text компании Vocapia - это передовая технология обработки речи, которая обеспечивает непрерывное распознавание речи с большим словарным запасом на нескольких языках для различных типов аудиоданных.
Он позволяет транскрибировать большое количество аудио- и видеодокументов, таких как данные вещания, как в пакетном режиме, так и в режиме реального времени. Он также обеспечивает сегментацию и разделение аудио, идентификацию диктора и распознавание языка.
Программный комплекс доступен в виде веб-сервиса через REST Speech-to-Text API, предлагая возможности полной транскрипции речи, индексирования аудио и выравнивания речи и текста через REST API по HTTPS.
Кроме того, программное обеспечение предлагает передовые языковые технологии, такие как идентификация языка и дикторская диаризация, для преобразования необработанных аудиоданных в структурированные и доступные для поиска XML-документы, что позволяет пользователям получать доступ к содержимому видеодокументов.
Оно используется в таких приложениях, как поиск данных для вещания и телефонной связи, речевая аналитика, мониторинг СМИ, управление медиаактивами, транскрипция речи, субтитрирование и многое другое.
Программное обеспечение для распознавания речи доступно для более чем 82 языков, и клиенты могут создавать модели для желаемого набора языков.
Поддержка русского языка – есть.
•

Gladia - это нейросеть, которая предоставляет подключаемые API, позволяющие пользователям извлекать максимальную пользу из своих данных. API Speech-to-Text API Alpha - это их последнее предложение, которое предлагает обработку в режиме реального времени и коэффициент ошибок в словах не превышает 1%.
Он создан на основе моделей Whisper Models компании Open AI и способен расшифровать один час аудио всего за 10 секунд.

API доступен бесплатно и поддерживает 99 языков.
Поддержка русского языка – есть.
Автор: pimka21
Еще советуем:
